1. Introduction
Ayant eu la chance d’être un témoin privilégié des travaux de recherche de Patrice Dalle sur le traitement automatique de la langue des signes française (LSF), je retrace dans cet article les contributions les plus marquantes de ses travaux au travers des projets auxquels il a participé et des thèses qu’il a dirigées.
Patrice a débuté sa carrière à l'Université Paul Sabatier de Toulouse au sein du laboratoire IRIT1 (Institut de Recherche en Informatique de Toulouse de l’Université Paul Sabatier) sur la conception de systèmes d'interprétation d'image, tout en dispensant des cours d'informatique et de traitement et d'analyse d'image. Après avoir soutenu son habilitation à diriger les recherches en 2000 (DALLE, 2000), il a orienté ses recherches vers le traitement automatique de la LSF tout en conservant en parallèle une très forte implication en tant que militant associatif auprès des associations IRIS2 (Institut de Recherche et d’Innovation en Langue des Signes) et ANPES3 (Association Nationale des Parents d’Enfants Sourds). Cela a eu un impact fort dans la manière dont il a orienté ses travaux et les applications potentielles de ses résultats de recherche.
Cet article propose un tour d’horizon de ses travaux structuré en cinq périodes et thématiques. La section suivante (section 2) présente une première période consacrée au premier projet et à la première thèse qui s’est centrée en particulier sur la modélisation de l’espace de signation. Les sections suivantes sont consacrées aux travaux qui ont suivi sur l’étude des vidéos de LSF, plus particulièrement sur la modélisation et suivi du corps du signeur (section 3), puis sur la modélisation et le traitement automatique d’unités gestuelles en LSF (section 4). La section 5 concerne des travaux portant sur l’étude des formes écrites des LS, plus particulièrement SignWriting (SW). Une dernière section (section 6) décrit les projets de recherche régionaux étroitement liés à l’enseignement en LSF et qui ont permis de rassembler et compléter l’ensemble des logiciels issus des contributions de recherche de Patrice et ses doctorants au sein de la suite logicielle LogiSignes. L’article se termine par une conclusion en forme d’hommage à Patrice Dalle et à son apport en recherche sur le traitement automatique des langues des signes (TALS) appliquée à la conception d’outils pédagogiques pour l’enseignement en LSF.
2. Le début des années 2000 : le premier projet et la première thèse
Dès le début de son investissement dans le domaine du TALS, Patrice a participé à des projets collaboratifs. On peut citer en particulier le projet LS-COLIN4 (Langues des Signes - COgnition, Linguistique, Informatique), piloté par Christian Cuxac, linguiste spécialiste de la LSF professeur à l’Université Paris 8. Le nom complet du projet était « Langues des signes : Analyseurs privilégiés de la faculté de langage ; apports croisés d'études linguistiques, cognitives et informatiques (traitement et analyse d'image) autour de l'iconicité et de l'utilisation de l'espace ». Le consortium était composé de chercheurs du LIMSI (CNRS), de l’IRIT et du CAMS (Université Paris 4). Il a été financé de 2000 à 2002 dans le cadre d’une Action Concertée Incitative Cognitique du ministère de la recherche.
Ce projet a été le premier permettant aux linguistes et informaticiens de travailler de concert sur la LSF. Une des contributions majeures a été la création d’un corpus de LSF pour les recherches interdisciplinaires sur la LSF (BRAFFORT et al., 2001). Ce corpus, nommé aussi LS-COLIN, a nourri de nombreux travaux en linguistique (SALLANDRE, 2003) mais aussi en informatique, avec des études combinant des méthodes issues des deux disciplines (linguistique et informatique). Cela a concerné en particulier l’annotation de corpus à des fins d’analyse linguistique et informatique. Par exemple, la figure 1 montre un extrait d’une vidéo de LS-COLIN annoté avec le logiciel ANVIL. La première piste comporte des annotations linguistiques et les pistes suivantes, des courbes représentant le mouvement de différentes parties du corps dans les différents plans des trois caméras.
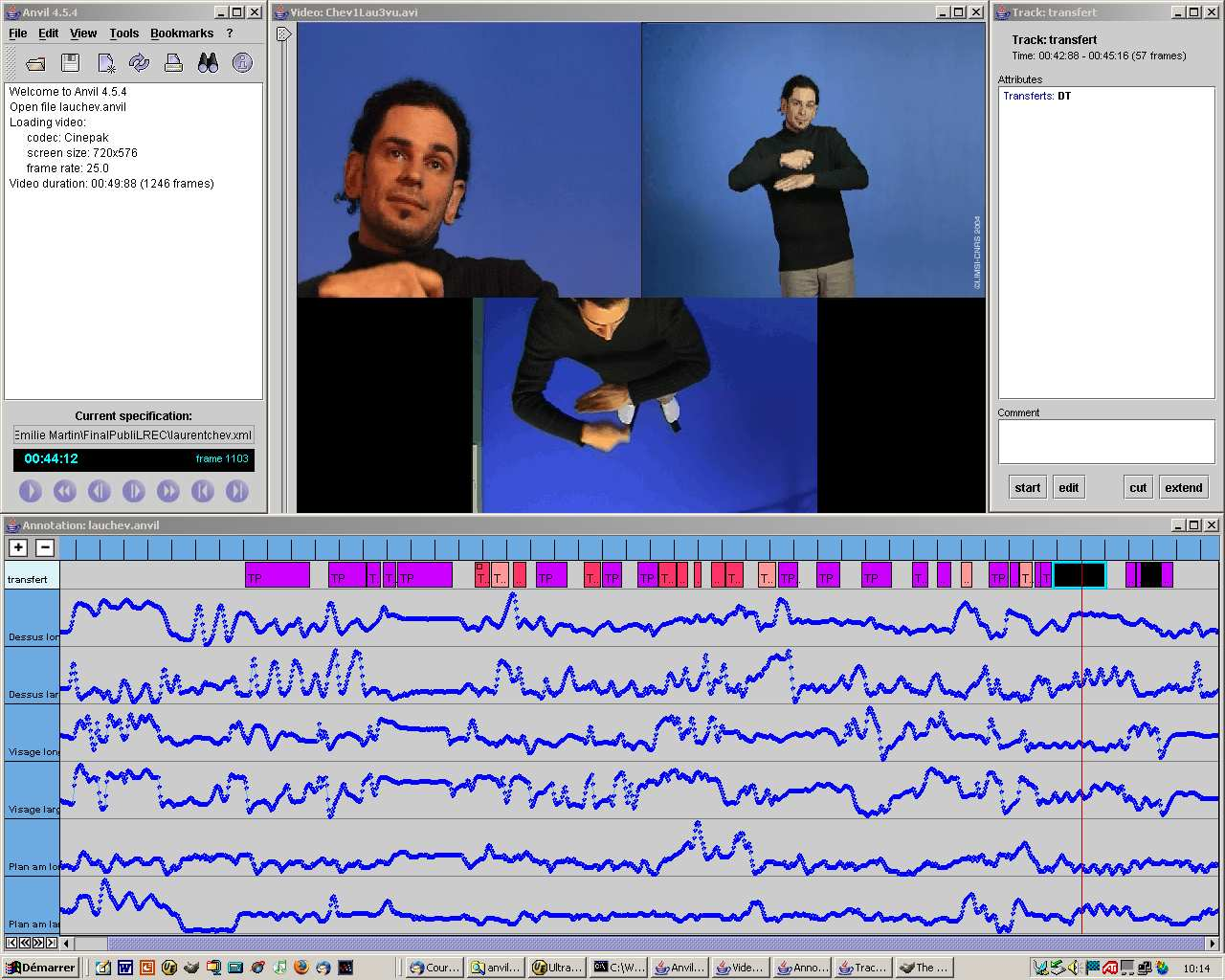
Figure 1. Annotation d’une vidéo issue du corpus LS-COLIN combinée avec des méthodes issues du traitement d’images (SEGOUAT, et al., 2006, 1998).
Dans le domaine du TALS, Patrice s’est plus particulièrement intéressé à des questions de recherches autour des vidéos de LSF. Cela a commencé par la définition d’un premier sujet de thèse intitulée « Intégration de connaissances linguistiques dans un système de vision : application à l'étude de la langue des signes ». Elle a été menée par Boris Lenseigne et soutenue en 2004 (LENSEIGNE, 2004).
Il s’agissait de concevoir un système dédié à l’analyse de séquences vidéos de la LSF. L’idée était d’intégrer des connaissances linguistiques issues des travaux de Christian Cuxac sur deux aspects : le fait que la structure de l’énoncé peut être déduite de façon directe de l’agencement des entités que le signeur positionne dans l’espace de signation et le fait que la construction des structures sémantiques dans cet espace fait appel à des structures grammaticales bien définies.
Une des contributions principales de cette thèse a été une proposition de modélisation associée à une représentation 3D de l’espace de signation, dans laquelle peuvent être représentés le signeur (en bleu figures 2 et 3) et les entités du discours, avec un code de forme et de couleur selon leur type : lieu (cercle jaune), date (croix blanche), objet (cube vert), personne (cylindre rouge) et action (flèche noire).
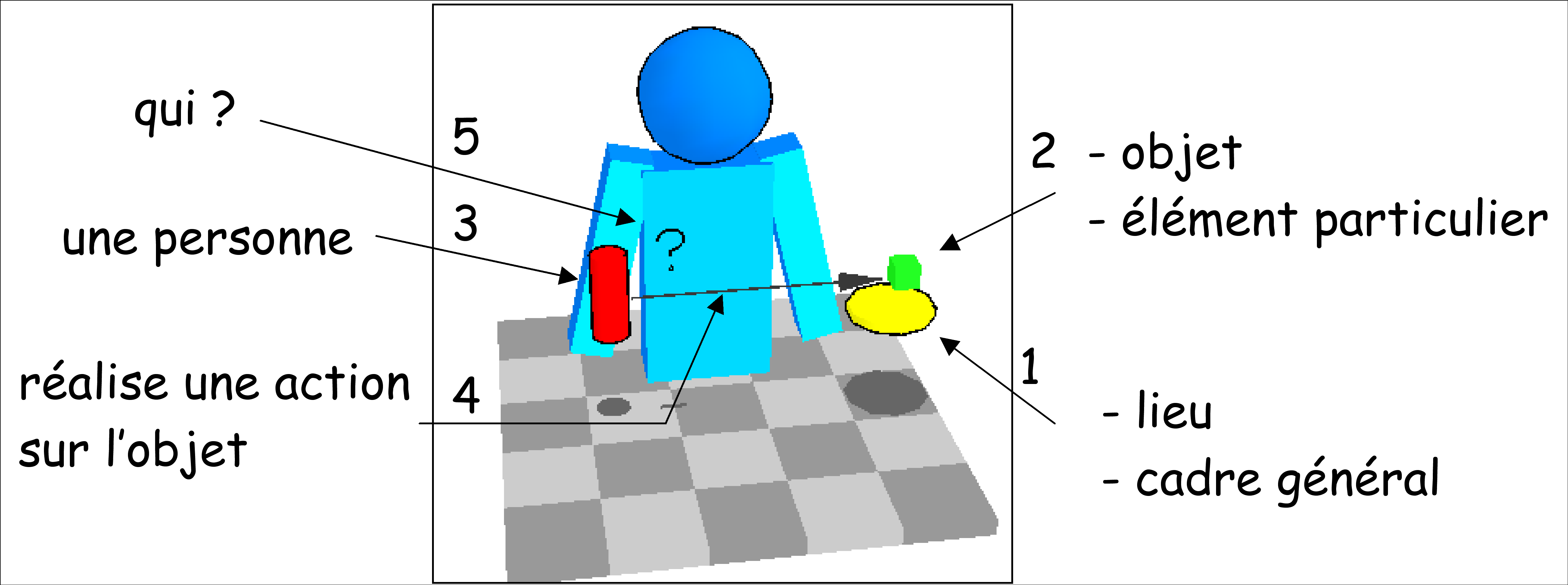
Figure 2. Représentation 3D de l’espace de signation et code visuel de représentation des entités et de leur fonction dans un discours en LSF (LENSEIGNE, 2004, 235).
Cette modélisation permet de représenter la manière dont un énoncé est élaboré et structuré spatialement. A titre d’exemple, la figure 3 montre les 9 étapes successives de l’élaboration d’un énoncé produit en LSF que l’on pourrait traduire en français par « Quel est le nom du réalisateur du film qui passe à l’Utopia Toulouse le jeudi 26 février à 9h30 ? ».
Sept étapes de l’élaboration de la représentation de cet énoncé sont représentées successivement dans la première, puis la deuxième colonne.
La première colonne comporte 4 étapes :
-
le positionnement d’un premier lieu à la gauche de la locutrice : Toulouse (cercle jaune),
-
le positionnement d’un deuxième lieu superposé au premier : Le cinéma Utopia (cercle jaune),
-
le positionnement d’une entité toujours au même endroit : le film (cube vert),
-
une date et une heure : Jeudi 26 février à 9h30 (croix grise).
La colonne de droite comporte 3 étapes :
-
le positionnement d’une personne : celui (cylindre rouge),
-
la création d’une relation entre la personne et l’entité film : a fait le film (flèche noire),
-
la question : c’est qui (symbole?).
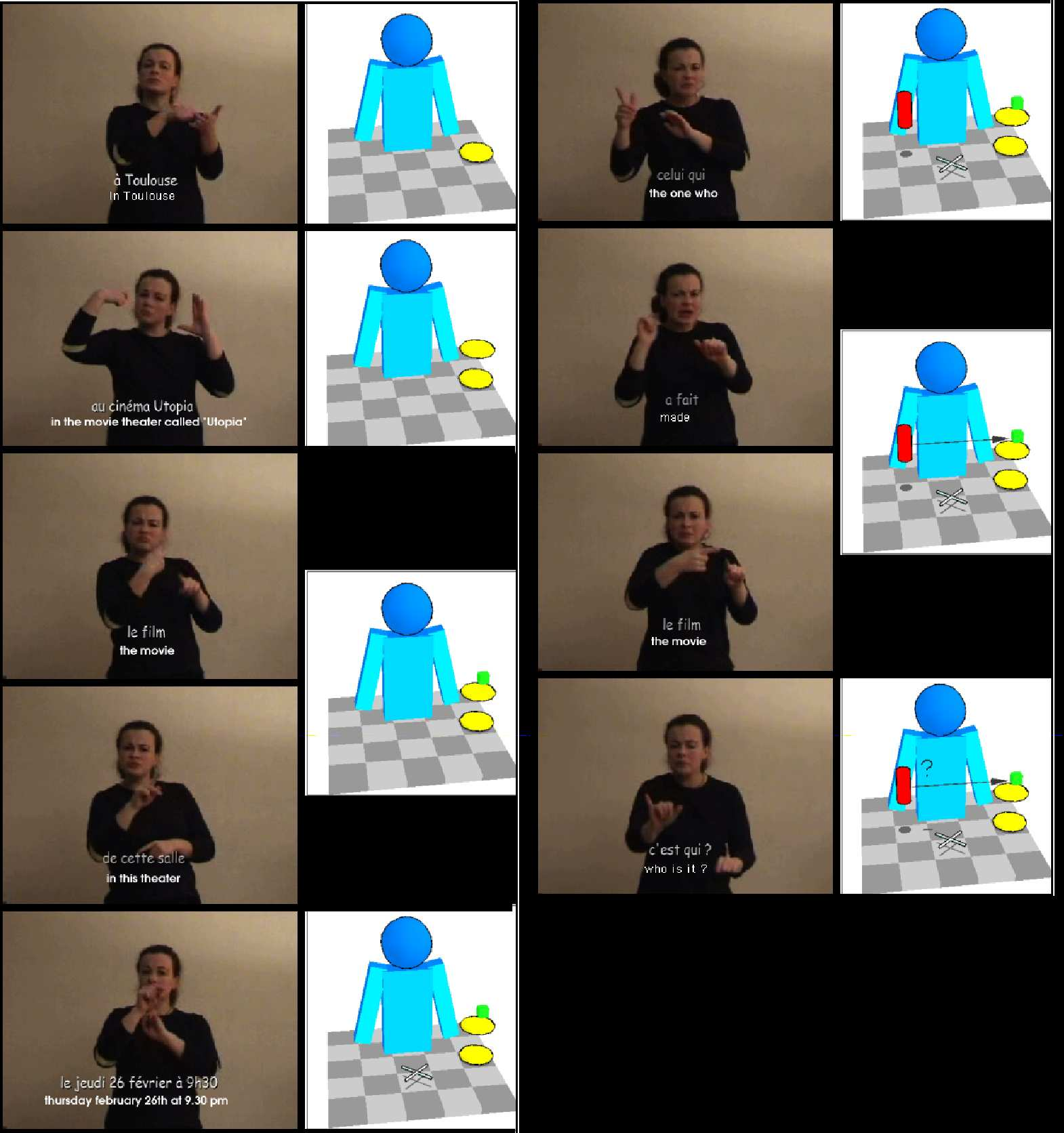
Figure 3. Séquence de structuration de l’espace de signation pour l’énoncé en LSF pouvant être traduit en français par « Quel est le nom du réalisateur du film qui passe à l’Utopia Toulouse le jeudi 26 février à 9h30 ? » (LENSEIGNE, 2004, 112).
Dans le cadre de cette thèse, un logiciel nommé VIES (Visualisation Interactive de l’Espace de Signation) a été implémenté. Il permet d’éditer les différentes étapes de structuration spatiale d’un énoncé en LSF. Il a été intégré dans la suite logicielle LogiSignes décrite en section 6.
Cette première période a permis de mettre en place des méthodes de recherche sur l’élaboration de corpus, sur l’annotation et la modélisation informatique basées sur des connaissances linguistiques. Cette démarche interdisciplinaire a été dès le début très importante pour Patrice. Il a d’ailleurs participé à l’animation de cette interdisciplinarité au niveau national. Il a par exemple créé un corpus de dialogue en LSF en partenariat avec IRIS, qui a été ensuite utilisé dans le cadre du tout premier atelier national dédié au TALS5, adossé à la conférence de Traitement Automatique des Langues Naturelles (TALN) en 2005. L’objectif de l’atelier était de permettre aux chercheurs de présenter et d’échanger leurs idées et les résultats de leur recherche. Il était ouvert à toutes les disciplines s'intéressant à la modélisation ou au traitement de la Langue des Signes : linguistique, informatique, sciences cognitives. Il s'est déroulé sur une journée et la matinée a été consacrée à des échanges autour de ce corpus de dialogue mis à disposition des participants (BRAFFORT, et al., 2005).
Les deux périodes suivantes ont porté plutôt sur des questions de recherche liées à la détection automatique du contenu dans les vidéos, avec une première phase sur le suivi du corps des signeurs (section 3) et une deuxième sur des aspects de plus haut niveau concernant plus directement la LSF (section 4).
3. Modélisation et suivi de composantes corporelles dans les vidéos de LSF
Avec l’objectif de repérer et analyser des parties du visage ou du corps dans le vidéos de LSF, deux thèses ont été soutenues en 2007.
La thèse de Hugo Mercier, intitulée « Modélisation et suivi des déformations faciales. Applications à la description des expressions du visage dans le contexte de la langue des signe » (MERCIER, 2007), s’est centrée sur le visage, qui joue un rôle prépondérant en LS. Dans cette thèse, il s’agissait de développer des méthodes permettant la description la plus précise et exhaustive possible des différents mouvements faciaux observables au cours d’une séquence vidéo de LSF. La figure 4 illustre un des aspects étudiés, consistant à conserver une représentation (le maillage en blanc) correcte des composants du visage en cas d’occultation par la main. L’image de gauche montre la déformation du maillage dû à la présence de la main devant le visage et l’image de droite montre l’amélioration obtenue après traitement.


Figure 4. Adaptation d’un modèle déformable (maillage blanc) lors de la présence d’occultation initialement (à gauche) et après traitement (à droite) (MERCIER, 2007, 78).
Une des applications visées était de pouvoir décrire une séquence vidéo à chaque instant par une combinaison de déformations afin de pouvoir décrire une expression du visage en LSF. Une autre était de transformer la vidéo de manière à empêcher l’identification d’un visage sans perturber la reconnaissance des expressions.
La thèse de Frédérick Gianni intitulée « Suivi de parties de corps pour l'interprétation de gestes de communication à partir de séquence monoculaire » (GIANNI, 2007) avait pour objectif, quand à elle, de proposer des méthodes de suivi de parties du corps dans une séquence vidéo. La figure 5 illustre un des aspects de ce travail qui consistait à repérer et suivre tout au long de la vidéo trois composantes corporelles : la tête et les mains. Dans cette figure, les résultats de deux méthodes sont visualisés : l’une d’elle, nommée filtre à particule simple, est représentée par les grands cercles ; l’autre, nommée filtre à particule recuit, représentée par les petits cercles, a permis d’obtenir des résultats plus précis.

Figure 5. Comparaison de deux méthodes pour suivre la tête et les mains du locuteur : un filtre à particule simple (grand cercle) et un filtre à particule recuit (petit cercle) plus précis (GIANNI, 2007, 145).
Ces travaux ont été eux aussi assez novateurs à l’époque, car l’analyse des composantes du corps humain dans les vidéos n’était quasiment pas exploré dans le cadre des LS. Avec les méthodes et outils disponibles à cette époque, il était difficile d’aboutir à des outils pleinement fonctionnels. Le développement récent de nouvelles méthodes d’intelligence artificielle à base d’apprentissage profond, a permis des progrès considérables dans ce domaine et permettraient certainement de dépasser les limites des travaux menés à cette époque.
4. Modélisation et traitement automatique des unités gestuelles en LSF
Durant la période suivante, Patrice a participé en particulier aux projets SignCom et Marqspat. Ces projets ont donné lieu à la création de corpus à l’aide de systèmes de capture de mouvement (mocap), permettant ainsi d’accéder à la troisième dimension et aussi de disposer de données précises sur les mouvements des différentes parties du corps (figure 6).
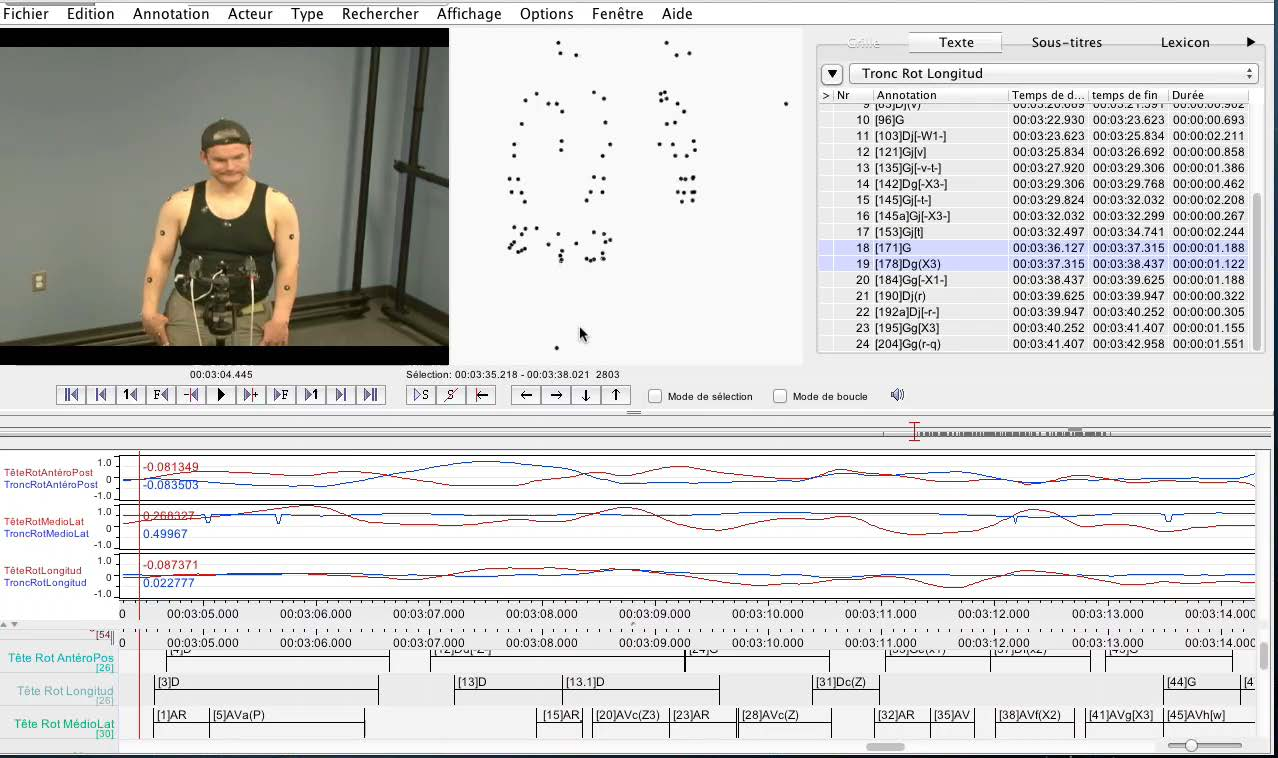
Figure 6. Annotation d’un extrait du corpus Marqspat dans le logiciel ELAN (PARISOT, et al., 2011).
Le projet SignCom, financé par l’ANR entre 2008 et 2011, visait à étudier l'interaction entre humains et avatar signant à travers un modèle de dialogue. Un corpus en LSF a été réalisé avec un système de capture de mouvement. Son thème principal portait sur les recettes de cuisine.
Le projet Marqspat, financé par le CFQCU (Fond Québécois) et le PARI (Université Paris 8) entre 2009 et 2012, visait à rendre compte des stratégies linguistiques pour localiser et mettre en lien les référents du discours dans la grammaire de trois langues des signes (LSQ, LSF, ASL), ainsi que dans la gestualité humaine. Ici aussi un corpus a été réalisé avec un système de capture de mouvement qui cette fois-ci incluait la détection du regard. Il s’agissait d’un corpus d’élicitations guidées et libres où le signeur répondait à des questions posées par l’interlocuteur en face de lui sur le contenu de vidéos projetées et sur des expériences personnelles similaires.
A ces deux corpus de mocap, se sont ajoutées les vidéos de brèves d’actualités produite par Websourd6 à partir des années 2005 et pendant une dizaine d’années. Ces brèves en LSF, correspondant à des traductions de brèves AFP (Agence France-Presse), ont aussi été et restent encore une source importante de données utiles à la recherche sur la LSF.
Les deux doctorants qui ont mené leur thèses durant cette période ont pu utiliser ces corpus dans leurs thèses consacrées au traitement automatique de vidéos sur des aspects de plus haut niveau directement en lien avec la LSF : les signes et les pointés.
La thèse de François Lefebvre-Albaret, soutenue en 2010 et intitulée « Traitement automatique de vidéos en LSF, Modélisation et exploitation des contraintes phonologiques du mouvement » (LEFEBVRE-ALBARET, 2010) a porté plus spécifiquement sur l’étude du mouvement, en particulier au sein des unités gestuelles lexicalisées : les signes. Il a étudié finement le mouvement des bras dans les corpus de mocap et a pu en déduire un modèle qu’il a ensuite appliqué à l’analyse des vidéos.Une des contributions de la thèse a été la réalisation d’un logiciel nommé Photosigne (figure 7). Son rôle est de faciliter la création d’images de signe en automatisant la génération de flèches et la fusion de plusieurs images prises dans la vidéo du signe (en gérant les transparences).
La création d’un photosigne suppose plusieurs étapes d’interaction entre l’utilisateur et le logiciel :
-
l’utilisateur doit spécifier la zone d’intérêt à suivre dans la vidéo, la dimension de la tête, ainsi que l’échelle du signeur, puis le suivi de la tête et des mains dans la vidéo est réalisé automatiquement ;
-
l’utilisateur doit sélectionner dans la vidéo les images et les membres à faire apparaître en transparence (image de début, image de fin, ou image en cours de signe) ;
-
il choisit ensuite le type de mouvement et de symétrie du signe ;
-
la génération des flèches est automatique. Elle est réalisée en traitant les données de suivi en fonction du type de signe ;
-
enfin, il est possible de déplacer les flèches dans l’image pour permettre une meilleure visibilité des mains du signeur.
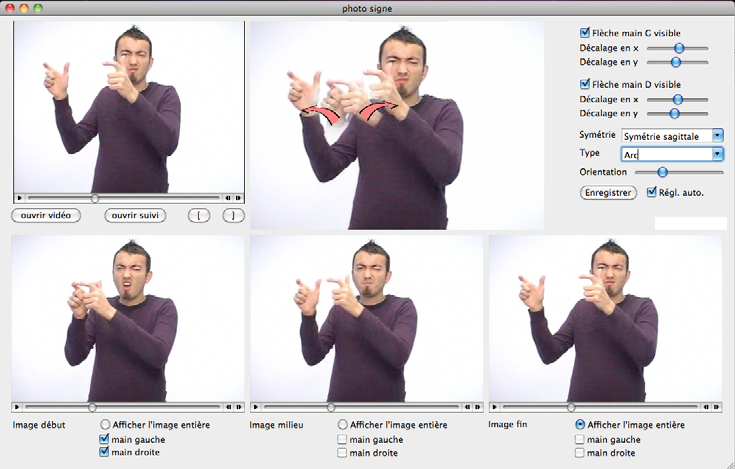
Figure 7. Interface de création d’un photosigne (LEFEBVRE-ALBARET, 2010, 181).
Ce logiciel a lui aussi été intégré dans la suite LogiSignes décrite en section 6.
La thèse de Monia Ben Mlouka était intitulée « Le référencement en Langue des signes : analyse et reconnaissance du pointé » (BEN MLOUKA, 2014). Elle a été soutenue en 2014, après le décès de Patrice. Sa thèse s’est centrée sur des unités gestuelles non lexicale, le pointé. La figure 8 montre deux réalisations possibles du pointé, avec un index tendu si l’espace pointé est un point de l’espace et une main plate s’il s’agit d’une zone plus étendue. Dans les deux cas la configuration de la main est accompagnée d’un mouvement et d’un regard dirigé sur l’endroit pointé.


Figure 8. Pointé avec un index tendu (à gauche) et une main plate (à droite) (BEN MLOUKA, 2014, 14).
Les travaux se sont basés ici aussi sur l’étude des corpus mocap et vidéo. Un des objectifs de la thèse était de tenter de détecter automatiquement des pointés dans une vidéo de LSF, ce qui est une tâche particulièrement complexe car ce type de geste est de très courte durée. L’originalité de ces travaux a été de s’appuyer sur des données de mocap pour proposer des modèles utilisés ensuite pour analyser des vidéos et ces travaux ont donc été eux aussi assez novateurs à l’époque. Comme précédemment, avec les méthodes et outils disponibles à cette époque, il était difficile d’aboutir à des outils pleinement fonctionnels et certaines limites rencontrées à l’époque pourraient sans doute être dépassées maintenant.
5. Autour de Sign Writing
A côté de ces projets centrés sur les vidéos, Patrice s’est aussi intéressé aux formes écrites pour les LS. Cette section rompt la progression chronologique car les études menées sur ce thème l’ont été à des périodes différentes.
Patrice a en effet participé au projet LS-SCRIPT, financé par l’ANR entre 2005 et 2007, dont l'objectif était de poser les bases d'une formalisation graphique de la LSF. Une première étape était de connaître les pratiques graphiques et les attentes de la communauté des sourds français par rapport à une éventuelle écriture de la LSF. Il a comporté de nombreuses études qui ont permis d'interroger les limites et l'applicabilité du formalisme SignWriting (SW) aux LS (BOUTORA, 2005). SW est un système de notation par symbole. Un signe est décrit par une vignette bidimensionnelle qui comporte la composition d’un ensemble de glyphes iconiques qui décrivent l’activité des articulateurs mis en jeu. Les glyphes sont très nombreux (environ 40 000) mais l’existence de groupes de glyphes prototypiques se déclinant selon des règles bien déterminées et leur iconicité peut permettre ainsi de les mémoriser.
Sur ce thème, deux thèses ont été soutenues. La thèse de Guylhem Aznar soutenue en 2008 et intitulée « Informatisation d'une forme écrite de la Langue des Signes Française » a proposé essentiellement une étude théorique sur le codage de caractères en vue de l’informatisation de SW (AZNAR, 2008). Celle de Fabrizio Borgia intitulée « Informatisation d’une forme graphique des Langues des Signes : application au système d’écriture SignWriting » a été soutenue en 2015, après le décès de Patrice (BORGIA, 2015). Elle était menée en co-tutelle avec l’Université La Sapienza à Rome et a poussé plus loin l’investigation sur SW.
Une des contributions de ce travail a été la réalisation du logiciel Swift (SignWriting improved fast transcriber). Il s’agit d’un éditeur qui permet d’écrire un contenu en SW (figure 9). Il a été développé avec l’objectif de répondre aux attentes des utilisateurs et donc en collaboration avec eux.
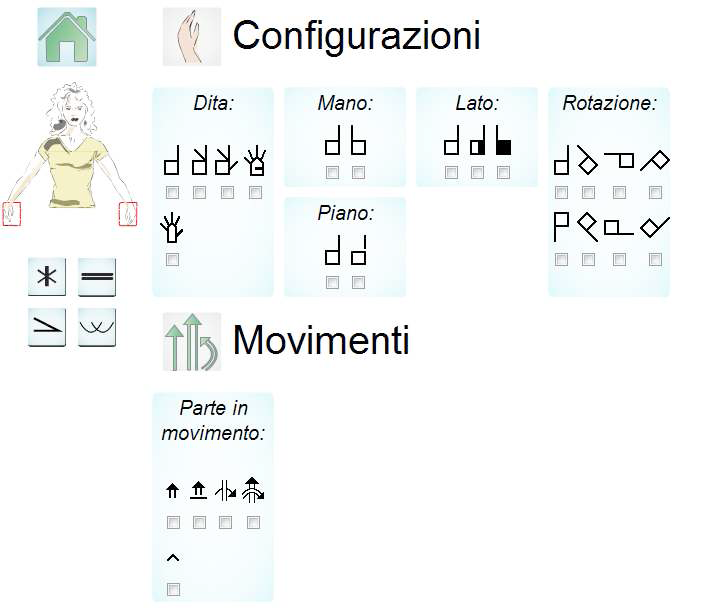
Figure 9. Menu des glyphes dédiés aux mains dans Swift (BIANCHINI, et al., 2012, 393).
Finalisé après le décès de Patrice et développé avec une interface en italien, il n’a pas été intégré dans la suite LogiSignes décrite dans la section suivante.
6. Les retombées des projets de recherche : les applications pédagogiques
On ne peut séparer l’implication associative de Patrice en lien avec l’enseignement en LSF pour les enfants sourds et ses travaux de recherche. Ainsi, au sein de l’IRIS, centre de formation à la LSF et d’expérimentation de différents services, il a conduit pendant plus de trente ans des expérimentations visant à étudier l’impact de l’introduction de la LSF et de professionnels sourds dans ces services. La réalisation la plus marquante a été la mise en place d’une filière complète (de la maternelle jusqu'à la terminale) d’enseignement en LSF, maintenant intégrée au dispositif ordinaire de l’Éducation nationale. Et de fait, les principales retombées des travaux de recherche qu’il a dirigé ont été des logiciels d’analyse de vidéos de LSF et des outils pour enseigner en LSF et fabriquer des documents pédagogiques en LSF ou bilingues (DALLE, 2013).
Ainsi, en plus des projets et thèses présentés précédemment, Patrice a coordonné plusieurs projets régionaux étroitement liés à l’enseignement en LSF, en rassemblant selon les projets certains des acteurs toulousains très actifs dans le domaine : l’IRIT, le CETIM, IRIS, Interprétis, VISUEL-LSF et Websourd.
Le projet SESCA (Système pour l’Enseignement de la langue des Signes et la Communication par Avatar), financé de 2007 à 2009, a permis de développer les outils pédagogiques, AVV et SLAnnotation, dédiés respectivement à l’enseignement et à l’analyse de la LSF. AVV est un logiciel créé à l’origine pour permettre aux professeurs de LSF de corriger les productions de leurs élèves en incluant des vignettes vidéos directement dans la vidéo de l’élève, ce qui constitue en quelque sorte un sous-titrage en LSF. Dans la pratique, d’autres usages sont apparus, tels que la réalisation de supports de cours. SLAnnotation est un logiciel d’annotation de vidéos qui a la particularité de permettre aussi d’annoter en LSF.
Le projet UVED7 (Université Virtuelle pour l’Environnement Durable), financé de 2010 à 2011, a permis de pousser plus loin la réflexion sur la place de la représentation graphique des signes dans les documents bilingues par le biais de l’outil Hypersigne (DALLE, 2012). Un hypersigne est l’équivalent d’un hypertexte, mais pour les vidéos de LSF. Il permet une navigation dans un document multimédia qui combine vidéo en LSF et texte, en établissant des liens directs entre éléments (textes, vidéos, images), au sein d’un même document ou de documents différents. Les hypersignes sont représentés de plusieurs manières dans le document : photosignes, segments colorés sous la vidéo, segments de textes colorés sur la droite du document, comme illustré figure 10.
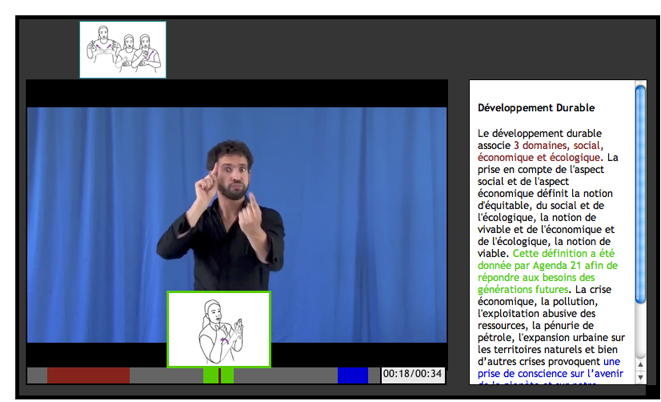
Figure 10. Extrait d’une vidéo sur le site UVED concernant le développement durable.
Enfin, le projet PRESTO8 (Pôle de Recherche Signes Tolosan), créé en 2008 et qui devait durer jusque 2015, prévoyait de rassembler et poursuivre des activités de recherche et d’expérimentation autour de la LSF, de ses usages et de son enseignement. On y trouve en particulier la suite LogiSignes9 qui rassemble cinq outils : AVV, PhotoSignes, SLAnnotation, VIES, HyperSignes, Lexique et AnimaS. Pour chacun d’eux il est possible de télécharger le logiciel et son mode d’emploi.
AVV, SLAnnotation et HyperSignes ont été présentés ci-dessus, VIES et PhotoSignes respectivement en sections 2 et 4. Lexique permet de créer des signaires bilingues qui peuvent être utilisés dans des documents pédagogiques (cours, exercice, etc.). Et enfin AnImaS permet d’annoter une image à l’aide d’une vidéo en LSF. Certains de ces logiciels ont été repris sur le site de l’association Dalle-LogiSignes10 dont l’objectif est de contribuer au développement, à l’évaluation et à l’appropriation d’outils et de ressources numériques au LSF en poursuivant et mutualisant les logiciels de la suite LogiSignes.
7. En guise d’hommage
J’ai tenté ici de retracer le parcours de chercheur de Patrice tout au long de ces années durant lesquelles il s’est consacré au TALS et pendant lesquelles nous avons très régulièrement collaboré sur des projets, des évènements, ou tout simplement fait des points d’avancées des travaux de nos équipes respectives. Notre toute dernière collaboration s’est faite au travers de la rédaction d’un ouvrage interdisciplinaire présentant une vue d'ensemble de la recherche sur la LSF à cette époque, en la replaçant dans le contexte international. Un collectif de linguistes et d’informaticiens y ont proposé un état des lieux de la recherche sur la LSF (BRAFFORT, 2016). Patrice a coordonné la rédaction du chapitre 5 consacré aux « Ressources et logiciels pédagogiques pour enseigner en LSF ». Il n’a malheureusement pas pu voir l’ouvrage édité. En son hommage, les droits d’auteurs de cet ouvrage sont versés à l’association Dalle-LogiSignes.
Le domaine de recherche en traitement automatique des langues des signes est très récent si on le compare à celui dédié aux langues écrites ou parlées. Il reste encore beaucoup à faire avant de pouvoir analyser et comprendre le contenu de vidéo de LS et détecter et analyser toutes les structures linguistiques spécifiques de ces langues. Si de nombreuses questions de recherche restent posées, il est certain que Patrice a été précurseur sur bien des aspects. Mais son apport unique est sa volonté indéfectible de défendre la LSF comme langue d’enseignement et de travail, ce qui l’a amené à mettre dès le début ses recherches au service du développement d’outils à destination de professionnels enseignants travaillant en LSF.
Ces logiciels ont été développés en tenant compte des besoins spécifiques à chaque profession, ce qui a permis d’aboutir à des outils qui sont réellement utilisés en situation d’enseignement. Certains sont cependant assez génériques pour répondre potentiellement à d’autres situations d’utilisation de la LS (LEFEBVRE-ALBARET, et al. 2010) et, en utilisant les progrès réalisés ces dernières années en intelligence artificielle, ils pourraient dans le futur être déclinés pour des usages plus larges encore, perpétuant ainsi l’héritage scientifique laissé par Patrice Dalle.
Dans ce parcours exemplaire et unique, qui est à son image, à la fois chercheur et militant, Patrice a su préserver ses deux facettes sans trahir ni l’une ni l’autre.